Analisis Leksikal, Automata dan Pohon Urai
Mohamad Tanwirul Akbar
202131066
Analisis Leksikal, Automata dan Pohon Urai
Analisis Leksikal
Analisis Leksikal merupakan
antarmuka antara kode program sumber dan analisis sintaktik (parser). Scanner
melakukan pemeriksaan karakter per karakter pada teks masukan, memecah sumber
program menjadi bagian-bagian disebut Token.
Analisis Leksikal mengerjakan pengelompokkan urutan-urutan karakter ke dalam
komponen pokok: identifier, delimeter, simbol-simbol operator, angka, keyword,
noise word, blank, komentar, dan seterusnya menghasilkan suatu Token Leksikal
yang akan digunakan pada Analisis Sintaktik.
Implementasi Analisis Leksikal
1. Pengenalan Token
- Scanner harus dapat mengenali
token
- Terlebih dahulu dideskripsikan
token-token yang harus dikenali
2. Pendeskripsian Token
- Menggunakan reguler grammar.
Menspesifikasikan aturan-aturan pembangkit token-token dengan kelemahan reguler
grammar menspesifikasikan token berbentuk pembangkit, sedang scanner perlu
bentuk pengenalan.
- Menggunakan
ekspresi grammar. Menspesifikasikan token-token dengan ekspresi reguler.
- Model matematis yang
dapat memodelkan pengenalan adalah finite-state acceptor (FSA) atau finite
automata.
3. Implementasi Analisis Leksikal
sebagai Finite Automata
Pada pemodelan analisis leksikal
sebagai pengenal yang menerapkan finite automata, analisis leksikal tidak cuma
hanya melakukan mengatakan YA atau TIDAK. Dengan demikian selain pengenal, maka
analisis leksikal juga melakukan aksi-aksi tambahan yang diasosiasikan dengan
string yangsedang diolah.
Analisis leksikal dapat dibangun
dengan menumpangkan pada konsep pengenal yang berupa finite automata dengan
cara menspesifikasikan rutin-rutin (aksi-aksi) tertentu terhadap string yang
sedang dikenali.
4. Penanganan Kesalahan di Analisis
Leksikal
Hanya sedikit kesalahan yang
diidentifikasi di analisis leksikal secara mandiri karena analisis leksikal
benar-benar merupakan pandangan sangat lokal terhadap program sumber. Bila
ditemui situasi dimana analisis leksikal tidak mampu melanjutkan proses karena
tidak ada pola token yang cocok, maka terdapat beragam alternatif pemulihan.
yaitu:
- "Panic mode" dengan
menghapus karakter-karakter berikutnya sampai analisis leksika menemukan token
yang terdefinisi bagus
- Menyisipkan karakter yang hilang
- Mengganti karakter yang salah
dengan karakter yang benar
- Mentransposisikan 2 karakter yang
bersebelahan.
Salah satu cara untuk menemukan
kesalahan-kesalahan di program adalah menghitung jumlah transformasi kesalahan
minimum yang diperlukan untuk mentransformasikan program yang salah menjadi
program yag secara sintaks benar.
Pohon urai
Sebuah parse tree atau parsing pohon atau pohon
derivasi atau pohon sintaks beton adalah
memerintahkan, berakar pohon yang mewakili sintaksis struktur string yang menurut
beberapa tata bahasa
bebas konteks . Istilah pohon parse sendiri
digunakan terutama dalam linguistik
komputasional ; dalam sintaksis teoretis, istilah pohon
sintaksis lebih umum.
Pohon sintaksis konkret mencerminkan sintaksis bahasa input, membuatnya
berbeda dari pohon sintaksis
abstrak yang digunakan dalam pemrograman komputer. Tidak
seperti diagram kalimat Reed-Kellogg
yang digunakan untuk mengajar tata bahasa, pohon parse tidak menggunakan
bentuk simbol yang berbeda untuk berbagai jenis konstituen .
Pohon parse biasanya dibangun berdasarkan baik hubungan konstituen tata
bahasa konstituen ( tata bahasa
struktur frase ) atau hubungan ketergantungan
tata bahasa dependensi . Pohon parse dapat dihasilkan
untuk kalimat dalam bahasa alami (lihat pemrosesan bahasa
alami ), serta selama pemrosesan bahasa
komputer, seperti bahasa pemrograman .
Konsep terkait adalah penanda frase atau penanda P ,
seperti yang digunakan dalam tata
bahasa generatif transformasional . Penanda frasa adalah
ekspresi linguistik yang ditandai dengan struktur frasanya. Ini dapat disajikan
dalam bentuk pohon, atau sebagai ekspresi kurung. Penanda frasa dihasilkan
dengan menerapkan aturan struktur
frasa , dan mereka sendiri tunduk pada aturan transformasional
lebih lanjut. Satu set pohon parse yang mungkin untuk kalimat ambigu sintaksis disebut "hutan
parse."

Sebuah pohon parse terdiri dari node dan
cabang. Pada gambar, pohon parse adalah seluruh struktur, mulai dari S dan
berakhir di setiap simpul daun (John, ball, the, hit). Dalam pohon parse,
setiap simpul adalah simpul akar , simpul cabang ,
atau simpul daun . Pada contoh berikut, S adalah simpul
akar, NP dan VP adalah simpul cabang, sedangkan John, bola, the, dan hit
semuanya adalah simpul daun.

Node juga dapat disebut sebagai parent node dan child node. Sebuah orangtua simpul adalah salah satu yang memiliki setidaknya satu node lain yang terhubung dengan cabang di bawahnya. Dalam contoh, S adalah induk dari NP dan VP. Sebuah simpul anak adalah salah satu yang memiliki setidaknya satu simpul langsung di atasnya yang dihubungkan oleh cabang pohon. Sekali lagi dari contoh kita, hit adalah simpul anak dari V.
Otomata
Otomata adalah mesin abstrak yang menggunakan
model matematika, tetapi matematika yang digunakan benar-benar berbeda
dibanding matematika klasik dan kalkulus. Model yang digunakan adalah model
mesin state (state machine model) atau model trnasisi state (state transition
model).
Terdapat 3 model komputasi pada teori otomata.
- Finite automata
- Pushdown automata
- Turing Machine
Memori Otomata
Otomata dibedakan berdasarkan jenis memori
sementara yang dimilikinya, yaitu:
- Finite automata (FA)
Tidak memiliki memori sementara. Finite automata
adalah kelas mesin dengan kemampuan-kemampuan paling terbatas.
- Pushdown automata (PDA)
Memiliki memori sementara dengan mekanisme LIFO
(Last In, First Out). Mesin ini lebih ampuh karena bantuan keberadaan stack yang
dipandang sebagai unit memori
- Turing Machine (TM)
Memiliki memori dengan mekanisme pengaksesan acak
(Random akses memori). Turing Machine merupakan model matematika untuk komputer
saat ini.
- Finite
Automata adalah mesin automata dari suatu Bahasa regular. Finite Automata
memiliki jumlah state yang banyaknya berhingga dan dapat berpindah-pindah dari
suate state ke state yang lainnya. Finite Automata dibagi menjadi Deterministic
Finite Automata (DFA) dan Non Deterministic Finite Automata (NFA).
Berikut contoh dari Deterministic Finite
Automata :
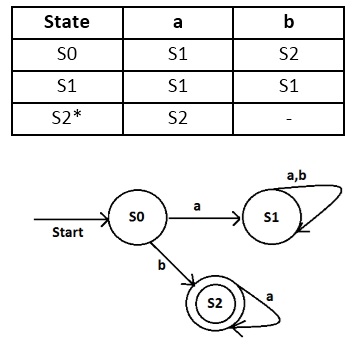
Berikut
contoh dari Non Deterministic Finite Automata (NFA) :


Berdasarkan
contoh Deterministic Finite Automata (DFA) dan Non Deterministic Finite
Automata (NFA) yang ada di atas, terlihat perbedaan antara DFA dan NFA yaitu :
·
Pada Deterministic Finite Automata, jika suatu state
diberi inputan maka state tersebut akan selalu tepat menuju satu state
·
Pada Non Deterministic Finite Automata, jika suatu
state diberi inputan maka mungkin saja bisa menuju ke beberapa state
berikutnya. Dapat dilihat di S0, jika diberi inputan b bisa menuju ke S1 dan
S2.
Contoh Program
Java
package latihan;
public class tugas {
public static void main(String[ ] args) {
System.out.println("Hello, World");
}
}
Analisis
Leksikal
- Pendeskrisian token :
latihan,
tugas merupakan identifiers
Package,
public, class, static, void, main, String, args, System.out.println merupakan keywords
Hello,
World merupakan literal
“{“, “}”, “[“,”]”, “(“, “)”, “;” merupakan punctuation
Analisis Pohon Urai

Keterangan : Pada level paling atas, terdapat sebuah package dengan nama latihan. Di dalam package tersebut terdapat sebuah class dengan nama tugas. Class tugas tersebut memiliki sebuah method dengan nama main. Pada method main tersebut terdapat sebuah perintah System.out.println("Hello, World");.
Analisis Automata

Otomata di atas menggambarkan
langkah-langkah yang dilakukan oleh program Java tersebut saat dijalankan.
Langkah pertama adalah program dimulai di state "start". Setelah itu,
program membaca statement "package
latihan" dan memindahkan dirinya ke "idle". Di
state "idle", program menunggu deklarasi class. Setelah class
dideklarasikan dengan nama “tugas”,
program memasuki state "main" dan menunggu eksekusi method
"main". Ketika method "main" dijalankan, program melakukan
output dengan statement "System.out.println". Akhirnya, program
selesai dengan output “Hello, World”.


Komentar
Posting Komentar